< Distilling the Knowledge in a Neural Network >
作为model compression系列中比较具有代表性的paper,选取这一篇做为开头。其实在这篇文章之前也有两篇是做出一定贡献的,不过不单独列出来写了,会在后文提到。
首先讲一下model compression的motivation:
其实应该是很直接的业界需求 - 一个很大的DNN往往训练出来的效果会比较好,并且多个DNN一起ensemble的话效果会更加的好,但是当用在实际的应用中的话,过于庞大的DNN ensemble在一起会增大计算量,从而影响应用。于是一个问题就被提出了:有没有一个方法,能使降低网络的规模,但是保持(一定程度上)精确度呢?
Hinton举了一个仿生学的例子,就是昆虫在幼生期的时候往往都是一样的,适于它们从环境中摄取能量和营养;然而当它们成长到成熟期,会基于不同的环境或者身份,变成另外一种形态以适应这种环境。那么对于DNN是不是存在类似的方法?在一开始training的过程中比较的庞杂但是后来当需要拿去deploy的时候,可以转换成一个更小的模型。他把这种方法叫做 Knowledge Distillation(KD)
Distillation
这里的distillation方法其实主要用的就是通过一个performance非常好的大网络(有可能是ensemble的)来教一个小网络进行学习。这里我们可以把大网络叫为:teacher network,小网络叫为:student network。
至于为什么是希望通过大网络来教小网络而不是直接利用grund truth label来学习,hinton也给了一个例子:比如说在MNIST数据集中,有两个数字“2”,但是写法是不一样的:一个可能写的比较像3(后面多出了一点头),一个写的比较像7(出的头特别的短)。在这样的情况下,gt label都是“2”,然而一个学习的很好的大网络会给label “3” 和 “7” 都有一定的概率值。通常叫这种信息为 “soft targets”;相对的,gt label 是一种 “hard target” 因为它是one-hot label。总的来说就是,通过大网络的“soft targets”,能得到更加多的信息来更好的训练小网络。
事实上,利用这个信息并不是这里的首创,< Do Deep Nets Really Need to be Deep? > 这篇paper就已经给出了利用logits(也是一个distribution over all the categories)做为训练目标。Hinton这里提出用一个更加完备的式子来利用,并且证明了,利用logits只是他这个式子的一个special case: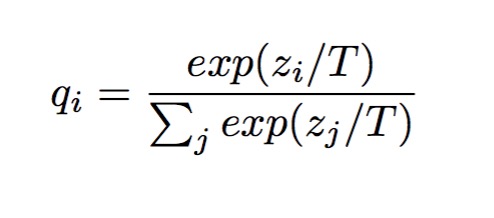

个人觉得加的这个参数temperature T的intuition是:
根据softmax函数的性质,当输入整体都放大N倍的话,尽管它们之前的比例不变,但是softmax的输出会变的特别极端(entropy降低);反过来,当整体缩小了的话,输出就会变的比较的soft,更方便学习。所以实际上Hinton的这个超参数T引入只是为了成功地生成这个“soft targets”。当然,如果T过大的话,也会使label变得不那么有区分性,效果也会差。所以这个Temperature也是需要调参的 xD
在实际的distillation过程中,最后的loss其实是于“soft targets” 和 correct label的一个加权和。
Practical Usage in Google
从这里开始Hinton介绍了在Google中对于一个巨大的数据集(JFT)所使用的deep learning方法。JFT数据集有一亿张图,共1万5千个类别,远远大于ImageNet。Google所做的baseline模型是一个很大的模型,在这些数据上训练了半年。对于这样一个数据集,试图通过ensemble的方法来提升模型性能的方法是不科学的,因为你得花费几年的时间才能训练出足够多的模型来ensemble。因此,google采取的方法是通过general model + specialist model 来做这件事。
specialist model是专注于某些容易混淆的类别所训练的模型,比方说蘑菇,平菇,香菇等等,可以去训练一个specialist model来做它们之间的判别。实际在这个specialist model的训练中,用50%的special类别的数据,另外50%是其他类别的数据,然后model的输出就会多一个dustbin的类。这样做的目的是为了防止overfitting。另外一个很重要的防止overfitting的方法,在第6节中阐述了,就是通过加进baseline模型的soft targets。